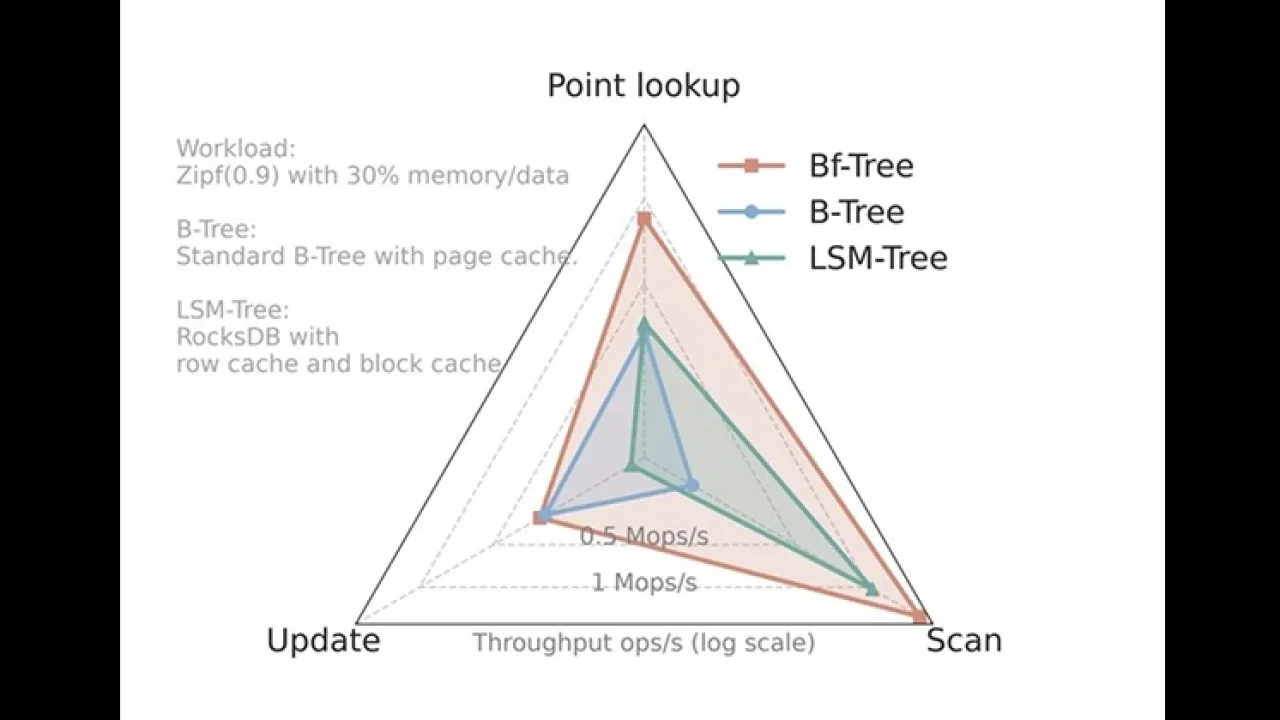
Yesterday, we focused on mini-pages and how redefining the leaf node allows Bf-Tree to absorb writes, cache hot records, and adapt to workload patterns without page-level overhead.
Today, we move up the tree.
Specifically, we look at inner nodes, a part of B-Trees that is often treated as an afterthought, but in practice sits directly on the critical path of every operation.
Conventional B-Tree implementations treat inner nodes and leaf nodes identically.
Both are:
This design choice has two major problems:
In real systems, inner nodes typically occupy less than 1% of the total tree size, yet they dominate access frequency.
Routing them through the same indirection layer as leaf pages turns the mapping table into a contention hotspot.
Bf-Tree makes a deliberate split between inner nodes and leaf nodes.
By default:
This has immediate benefits:
Because inner nodes are always resident in memory, the buffer pool no longer needs to account for them at all—it only manages leaf pages.
Importantly, this is a policy choice, not a hard requirement.
In memory-constrained deployments:
When an inner node is not pinned, it falls back to the same page-ID-based lookup used for leaf pages.
Even when pinned, inner nodes are still highly contended. Bf-Tree addresses this using optimistic latch coupling, based on a key observation:
Inner nodes are read constantly but modified rarely.
Modifications only occur during splits or merges.
Each inner node is protected by a compact 8-byte version lock:
This approach has a crucial performance advantage:
In practice, this allows inner nodes to remain hot, uncontended, and CPU-friendly—even under heavy parallel workloads.
Beyond node placement and concurrency control, Bf-Tree applies several layout-level optimizations uniformly across:
This consistency is intentional.
Each node begins with two special keys:
Together, these keys:
Instead of chained sibling pointers, Bf-Tree uses fence keys for their simplicity and predictable layout. The actual records follow these fence keys.
Keys in real systems: URLs, paths, identifiers often share long prefixes.
Bf-Tree exploits this by:
This:
When a full key is needed, the prefix is reconstructed by combining the fence-key prefix with the stored suffix.
Bf-Tree separates record metadata from actual key-value data. While this improves packing and locality, it introduces a potential cost during comparisons.
To mitigate this, each record stores the first two bytes of the key called look-ahead bytes—directly in the metadata.
During search:
Thanks to prefix compression, these first two bytes are usually enough to terminate comparisons early, avoiding unnecessary memory loads.
Mini-pages redefine how leaf nodes interact with memory and disk.
Pinned inner nodes redefine how navigation through the tree works.
Together, these choices eliminate:
Bf-Tree doesn’t just optimize pages, it separates concerns:
That separation is what allows the structure to scale cleanly on modern, highly concurrent hardware.
👉 Check out: FreeDevTools
Any feedback or contributors are welcome!
It’s online, open-source, and ready for anyone to use.
⭐ Star it on GitHub: freedevtools