Thinking Machines Tinker API Sheds Waitlist, Embraces Multimodality
SAN FRANCISCO (WHN) – Thinking Machines has moved its Tinker training API out of beta, a move that significantly lowers the barrier for AI engineers looking to fine-tune large language models. The update, rolling out in December 2025, ditches the waitlist and introduces support for OpenAI-compatible sampling and, critically, image inputs via Qwen3-VL vision language models.
This isn’t just about more models; it’s about abstracting away the complexities of distributed training. Tinker aims to let developers write straightforward Python code on a single CPU machine. The service then handles the heavy lifting, mapping that logic onto a GPU cluster and executing the specified computations. It exposes core primitives like `forward_backward` for gradient calculation and `optim_step` for weight updates, keeping the training logic explicit without the overhead of managing GPU failures or complex scheduling.
The underlying mechanism for model adaptation is Low-Rank Adaptation, or LoRA. Instead of retraining entire massive models, LoRA trains small adapter matrices on top of frozen base weights. This drastically reduces memory requirements and makes iterative experimentation on large Mixture-of-Experts (MoE) models far more practical within a shared cluster. This approach is key to making frontier model fine-tuning accessible.
The flagship change for December 2025 is the removal of the waitlist. Anyone can now sign up, review the current model catalog and pricing, and run provided examples directly. This democratizes access to fine-tuning capabilities that were previously out of reach for many smaller teams or individual researchers.
On the model front, Tinker now supports `moonshotai/Kimi-K2-Thinking`. This is a reasoning-focused MoE model boasting approximately 1 trillion parameters. Its design prioritizes long chains of thought and extensive tool usage, positioning it as the largest model currently available in Tinker’s catalog. It joins other models like Qwen3 variants, Llama-3, and DeepSeek-V3.1. The distinction between reasoning models, which generate internal thought processes before an answer, and instruction models, which prioritize direct, low-latency responses, is crucial for selecting the right tool for the job.
Tinker’s inference capabilities have also seen an upgrade. While it previously offered a native sampling interface, the new release adds a second pathway that directly mirrors the OpenAI completions API. This interoperability simplifies integration for developers already familiar with OpenAI’s ecosystem, allowing them to reference Tinker model checkpoints via URIs.
The second major addition is vision input. Tinker now exposes two Qwen3-VL models: `Qwen/Qwen3-VL-30B-A3B-Instruct` and `Qwen/Qwen3-VL-235B-A22B-Instruct`. These are listed as Vision MoE models and can be trained and sampled using the same API surface. Sending an image into a model involves constructing a `ModelInput` that interleaves `ImageChunk` objects with text chunks. The raw image data, along with its format (like PNG or JPEG), is passed in.
This multimodal pipeline is designed for consistency. Whether you’re performing supervised learning or reinforcement learning fine-tuning, the API representation for vision inputs remains the same, streamlining the development of multimodal pipelines. Crucially, these vision inputs are fully supported within Tinker’s LoRA training setup.
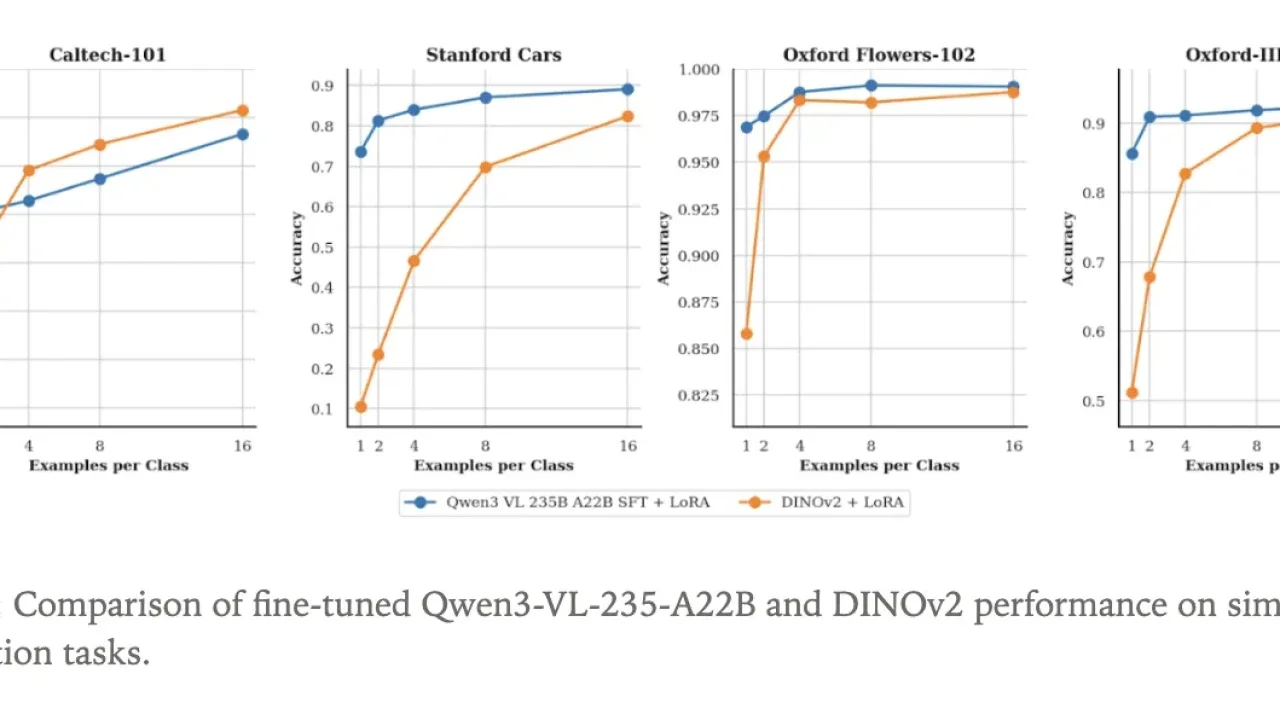
To demonstrate the new vision capabilities, the Tinker team fine-tuned `Qwen3-VL-235B-A22B-Instruct` as an image classifier. They leveraged four standard datasets for this experiment. Because Qwen3-VL is a language model with visual input, the classification task is framed as text generation: the model receives an image and outputs the class name as a text sequence.
As a comparative baseline, the team also fine-tuned a DINOv2 base model. DINOv2, a self-supervised vision transformer, encodes images into embeddings and often serves as a foundation for vision tasks. For this experiment, a classification head was attached to the DINOv2 backbone to predict label distributions. Both the Qwen3-VL model and the DINOv2 base were trained using LoRA adapters within Tinker, emphasizing data efficiency.
The experiment specifically tested performance with varying numbers of labeled examples per class, starting as low as one sample per class. Classification accuracy was measured at each increment. This focus on data efficiency highlights the potential for fine-tuning powerful multimodal models even with limited labeled data, a common bottleneck in AI development.